In the last weeks, I was running a number of tests based on the TPC-DS benchmark against Snowflake. One of the first thing I did is of course to create the TPC-DS schema and populate it. The aim of this blog post is to share some observations related to the population step.
The data I loaded was the same I used for this blog post (i.e. it is a 1 TB TPC-DS schema). The only difference was that I had to split the input files. This was necessary because Snowflake cannot parallelize the load with a single file. Therefore, for optimal performance, I had to split the large input files (the largest exceeds 400 GB). For example, by limiting the number of lines per input file to 1 million, the CATALOG_RETURNS table, instead of a single 22 GB input file, needs 144 input files of about 150 MB each. In addition, I also created compressed (gzip) versions of each input file. Note that all input files were stored in AWS S3.
The file format I used for the loads was the following:
CREATE OR REPLACE FILE FORMAT tpcds TYPE = CSV COMPRESSION = AUTO FIELD_DELIMITER = '|' ENCODING='iso-8859-1' ERROR_ON_COLUMN_COUNT_MISMATCH = FALSE
The load itself was carried out with the COPY statement. For example:
COPY INTO catalog_returns FROM @tpcds1t/catalog_returns/ FILE_FORMAT = tpcds PATTERN = '.*\.data'
To decide which virtual warehouse size to use for the full load, I ran a number of loads of the CATALOG_RETURNS table with sizes going from X-Small up to and including 2X-Large. Note that I did not test with 3X-Large and 4X-Large because I was not able to use them with my account. The following chart summarizes what I observed:
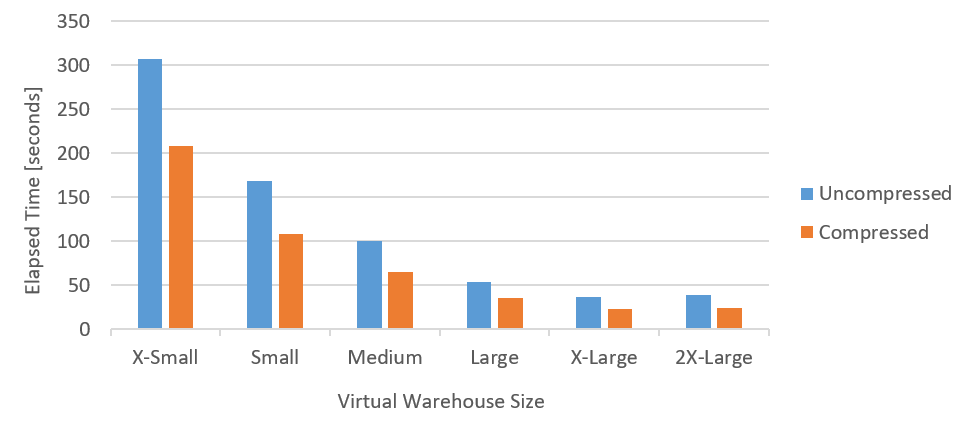
As you can see, except for 2X-Large (probably because of the limited size of the input data), as the size of the virtual warehouse increased (remember, for each “step” the number of credits doubles), the load time decreased of factor 1.5-1.9. Which, in my opinion, is rather good. In addition, with all virtual warehouse sizes, the load time of compressed input files decreased of factor 1.5-1.6 compared to uncompressed input files.
The last test I ran was loading the full 1 TB of data with a virtual warehouse of size 2X-Large. The data was stored in compressed (gzip) input files. Every input file contained at most 2.5 million rows. The load took 8 minutes. The following screenshot provides details:
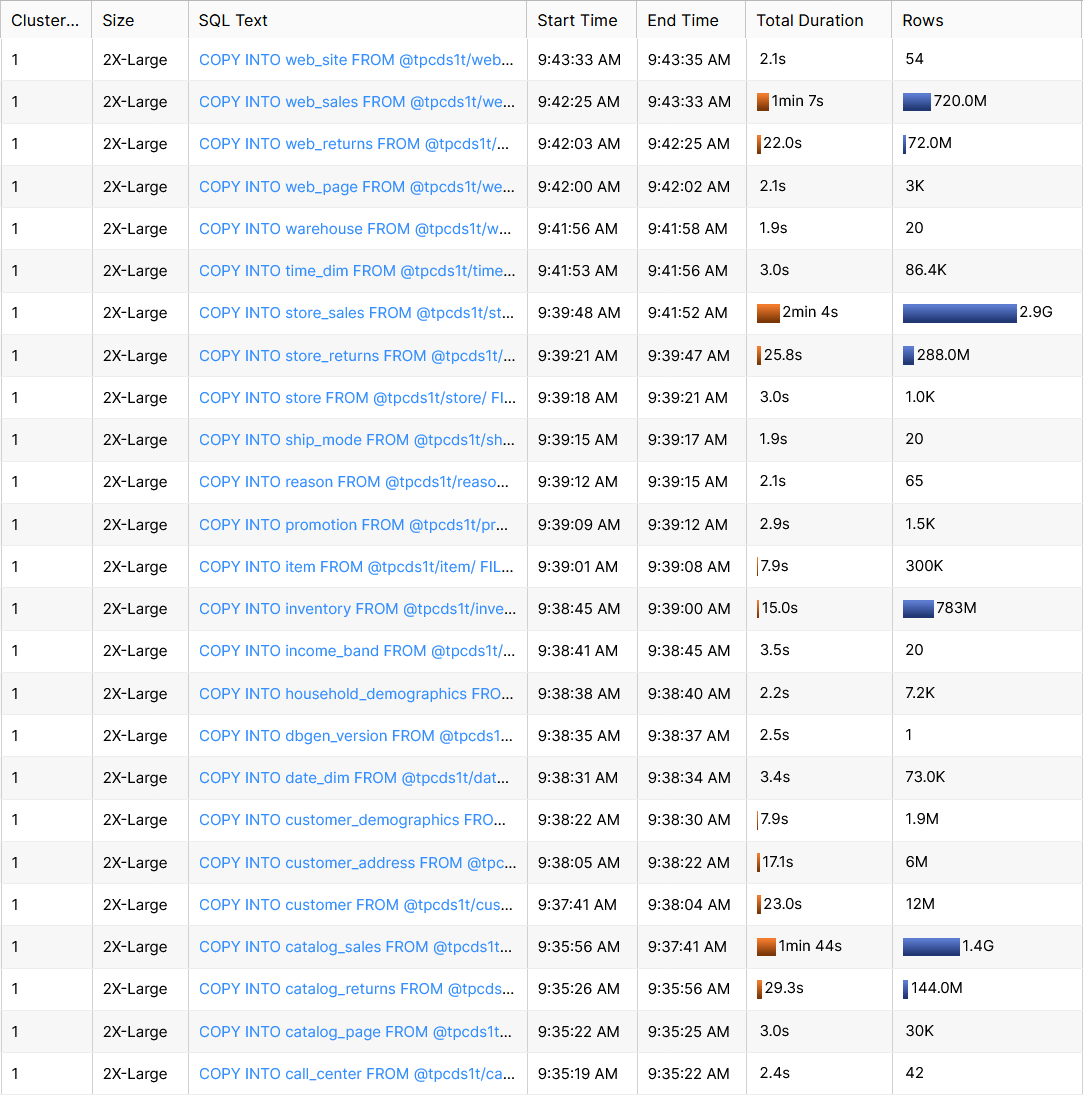
In summary, the loads I tested scaled well. In addition, I consider being able to load 1 TB of data in less than 10 minutes very good performance.