The aim of this post is not to explain how the APPROX_COUNT_DISTINCT function works (you find basic information in the documentation and in this post written by Luca Canali), but to show you the results of a test case I run to assess how well it works.
Here’s what I did…
I created a table with several numerical columns (the name of the column shows how many distinct values it contains), loaded 100 million rows into it (the size of the segment is 12.7 GB), and gathered the object statistics.
SQL> CREATE TABLE t 2 AS 3 WITH 4 t1000 AS (SELECT /*+ materialize */ rownum AS n 5 FROM dual 6 CONNECT BY level <= 1E3) 7 SELECT rownum AS id, 8 mod(rownum,2) AS n_2, 9 mod(rownum,4) AS n_4, 10 mod(rownum,8) AS n_8, 11 mod(rownum,16) AS n_16, 12 mod(rownum,32) AS n_32, 13 mod(rownum,64) AS n_64, 14 mod(rownum,128) AS n_128, 15 mod(rownum,256) AS n_256, 16 mod(rownum,512) AS n_512, 17 mod(rownum,1024) AS n_1024, 18 mod(rownum,2048) AS n_2048, 19 mod(rownum,4096) AS n_4096, 20 mod(rownum,8192) AS n_8192, 21 mod(rownum,16384) AS n_16384, 22 mod(rownum,32768) AS n_32768, 23 mod(rownum,65536) AS n_65536, 24 mod(rownum,131072) AS n_131072, 25 mod(rownum,262144) AS n_262144, 26 mod(rownum,524288) AS n_524288, 27 mod(rownum,1048576) AS n_1048576, 28 mod(rownum,2097152) AS n_2097152, 29 mod(rownum,4194304) AS n_4194304, 30 mod(rownum,8388608) AS n_8388608, 31 mod(rownum,16777216) AS n_16777216 32 FROM t1000, t1000, t1000 33 WHERE rownum <= 1E8; SQL> execute dbms_stats.gather_table_stats(user,'T')
Then, for every column, I ran two queries and measured the elapsed time, the maximum amount of PGA used by the query, and the precision of the result. Note that the test case was designed to avoid the usage of a temporary segment. In other words, all data required for the aggregation was stored into the PGA. As a result, the processing was CPU bound.
SELECT /*+ no_parallel */ count(DISTINCT n_2) FROM t
SELECT /*+ no_parallel */ approx_count_distinct(n_2) FROM t
Let’s have a look to three charts summarizing how well the APPROX_COUNT_DISTINCT function works:
- The first chart shows that for both functions the elapsed time depends on the number of distinct values. That said, while for the APPROX_COUNT_DISTINCT function the impact of the number of distinct values is minimal (the elapsed time goes from 5.8 up to 7.1 seconds), for the COUNT function it’s much higher (the elapsed time goes from 10.5 up to 35.2 seconds).
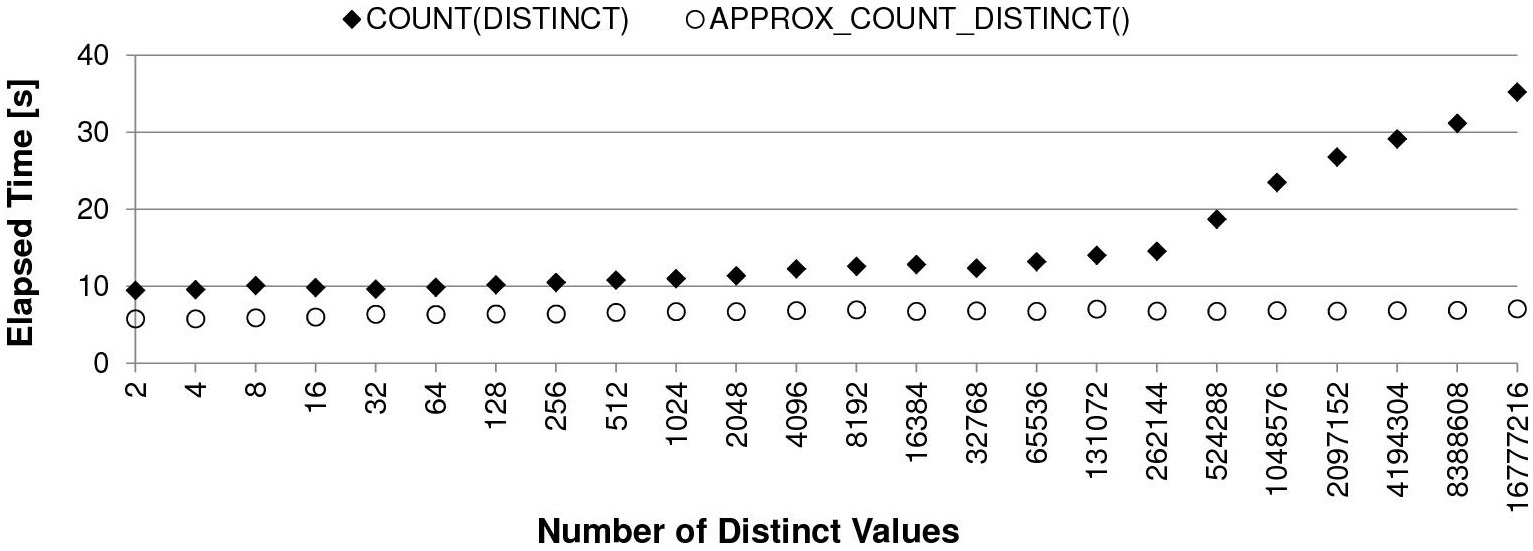
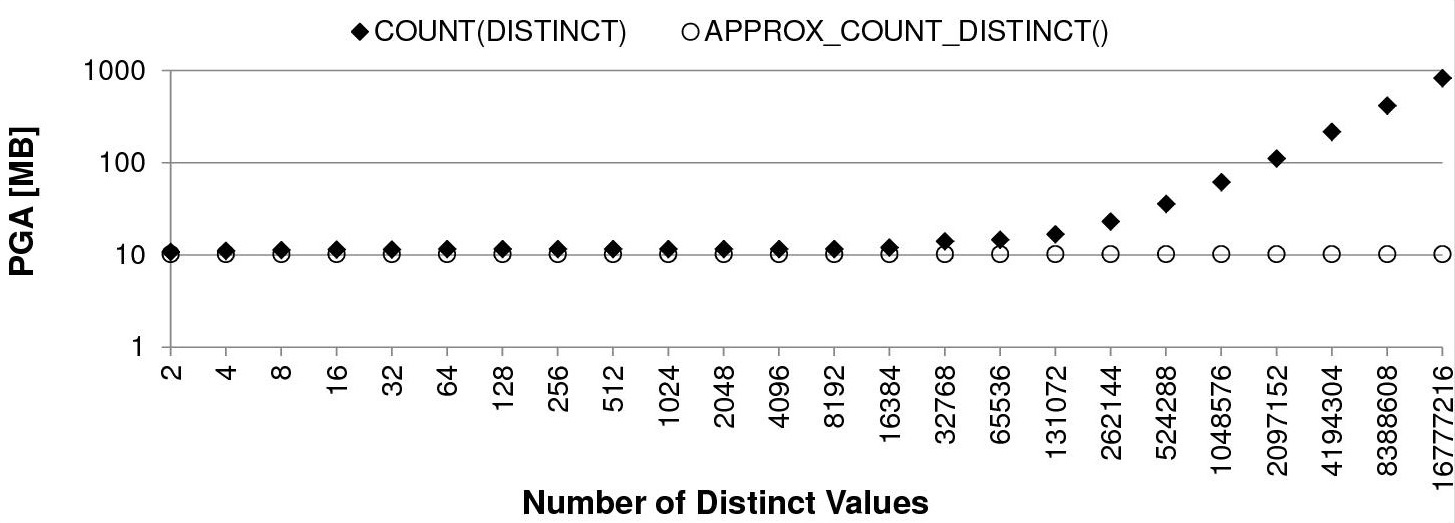
- The second chart (be careful that the y-axis scale is logarithmic) shows that only for the COUNT function the maximum amount of PGA depends on the number of distinct values (from 10MB up to 807MB). In fact, for the APPROX_COUNT_DISTINCT function, it was exactly the same (10MB) in all situations.
- The third chart shows that the precision of the APPROX_COUNT_DISTINCT function stays between -4% and +4%.
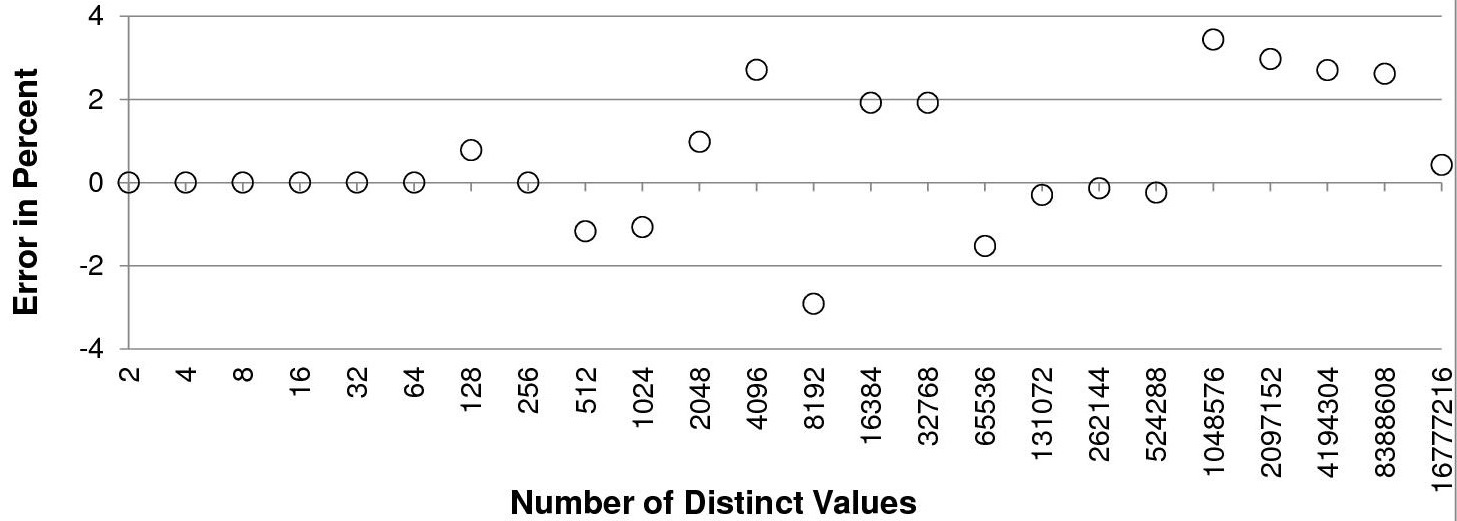
According to this test case, in my opinion, the performance and accuracy of the APPROX_COUNT_DISTINCT function with numerical values (I still have to test other data types) are good. Hence, I see no reason for not using it when an estimate of the number of distinct values is enough.
Wow! Very interesting! Thanks for publishing this, Chris.
Hi Chris!
Thanks for the interesting article!
One question: How did you make sure (“design the test case”) that no temp was used?
How did you check it?
Thanks,
Rob.
Hi Rob
I ran the queries and then checked, with a query like the following one, whether the foreground process experienced temp-related waits (e.g. “direct path write temp” and “direct path read temp”):
SELECT event, time_waited_micro
FROM v$session_event
WHERE sid=sys_context(‘userenv’,’sid’)
Cheers,
Chris
How does APPROX_COUNT_DISTINCT take less time for processing than normal count distinct? What is the processing happening behind APPROX_COUNT_DISTINCT which makes it more efficient?
Hi Praveen
It implements HyperLogLog. For detailed information have a look to the paper HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm.
Best,
Chris
[…] provides an approximate value without actually processing all of the database rows (Oak Table Network member and Oracle Ace Director Christian Antognini has documented consistent accuracy of plus-or-minus 4% with considerable performance […]
[…] http://antognini.ch/2014/10/the-approx_count_distinct-function-a-test-case/ […]
I get the following error with APPROX_COUNT_DISTINCT(). This doe snot occur with COUNT(DISTINCT …)
ORA-04036: PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT
04036. 00000 – “PGA memory used by the instance exceeds PGA_AGGREGATE_LIMIT”
*Cause: Private memory across the instance exceeded the limit specified
in the PGA_AGGREGATE_LIMIT initialization parameter. The largest
sessions using Program Global Area (PGA) memory were interrupted
to get under the limit.
*Action: Increase the PGA_AGGREGATE_LIMIT initialization parameter or reduce
memory usage.
Looks buggy… What’s the PGA consumption for both cases?