Recently I used the COMMIT_WAIT and COMMIT_LOGGING parameters for solving (or, better, working around) a problem I faced while optimizing a specific task for one of my customers. Since it was the first time I used them in a production system, I thought to write this post not only to shortly explain the purpose of the these two parameters, but also to show a case where it is sensible to use them.
The purpose of the two parameters is the following:
COMMIT_WAIT
- Simply put this parameter specifies whether a server process that issues a commit waits for the log writer while it writes the redo data in the redo log files.
- If it’s set to WAIT, the default value, the server process waits. And, in most situations, this is the best thing to do.
- If it’s set to NOWAIT, it doesn’t wait. This means that, in case of a crash just after a commit, the D of ACID might be violated! Hence, in general, it is not advised to use this value.
- If it’s set to FORCE_WAIT the behaviour is similar to WAIT. The only difference is that settings at a lower level are ignored. In other words, if it is set at the system level it overrides the setting at the session and transaction level. If it’s set at session level it overrides the setting at the transaction level.
COMMIT_LOGGING
- Simply put this parameter specifies whether the log writer writes redo data in batches.
- If it’s set to IMMEDIATE, the default value, it basically performs a write operation for each commit.
- If it’s set to BATCH, it writes redo data in batches. Since with this value less but larger write operations might be performed, in case of small transactions the log writer should be able to write the redo data in a more efficient way.
Note that in 10.2, the version that introduced these features, there is a single parameter (COMMIT_WRITE) to control them. For example, it is possible to set it to “NOWAIT, BATCH”.
To illustrates how these two parameters work I wrote two scripts: commit.sh and commit.sql. Their purpose is to show the number of times specific system calls are executed by the log writer and a server process that executes the following PL/SQL block:
DECLARE
l_dummy INTEGER;
BEGIN
FOR i IN 1..1000
LOOP
INSERT INTO t VALUES (i, rpad('*',100,'*'));
COMMIT;
SELECT count(*) INTO l_dummy FROM dual;
END LOOP;
END;
The two system calls I was interested in were the following:
- semtimedop(2): simply put this one is used by the server process to wait for the log writer
- io_submit(2): simply put this one is used by the log writer to write redo data in the redo log files
Let’s have a look the output generated by the scripts for three particular cases:
- COMMIT_WAIT = WAIT and COMMIT_LOGGING = IMMEDIATE: Notice that the server process executes 1005 times semtimedop(2) and that the log writer executes 1016 times io_submit(2). In other words, for both of them the number of executions is approximately the number of commits performed by the PL/SQL block.
oracle@helicon:~/commit/ [DBM11203] ./commit.sh chris ian wait immediate 2> /dev/null ***** Server Process ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.069561 69 1005 1 semtimedop ------ ----------- ----------- --------- --------- ---------------- 100.00 0.069561 1005 1 total ***** Log Writer ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.013919 14 1016 io_submit ------ ----------- ----------- --------- --------- ---------------- 100.00 0.013919 1016 total
- COMMIT_WAIT = NOWAIT and COMMIT_LOGGING = IMMEDIATE: Notice that, for the server process, the executions of semtimedop(2) dropped to 5. No noticeable difference is observable for the log writer.
oracle@helicon:~/commit/ [DBM11203] ./commit.sh chris ian nowait immediate 2> /dev/null ***** Server Process ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.002195 439 5 1 semtimedop ------ ----------- ----------- --------- --------- ---------------- 100.00 0.002195 5 1 total ***** Log Writer ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.010073 10 1015 io_submit ------ ----------- ----------- --------- --------- ---------------- 100.00 0.010073 1015 total
- COMMIT_WAIT = NOWAIT and COMMIT_LOGGING = BATCH: Notice that this time not only the number of executions to io_submit(2) dropped to 15, but, in total, much less time was spent for writing the redo data (10*1015 >> 36*15).
oracle@helicon:~/commit/ [DBM11203] ./commit.sh chris ian nowait batch 2> /dev/null ***** Server Process ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.002132 533 4 1 semtimedop ------ ----------- ----------- --------- --------- ---------------- 100.00 0.002132 4 1 total ***** Log Writer ***** % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000533 36 15 io_submit ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000533 15 total
Now that I explained what the purpose of these parameters is, let me describe a case where I successfully used them.
Few weeks ago one of my customers migrated its DMS to a new version. During the migration data had to be moved from one database to another. Unfortunately the migration code was written to process data slow by slow. Hence, to speed up the processing, parallelization was added to the picture.
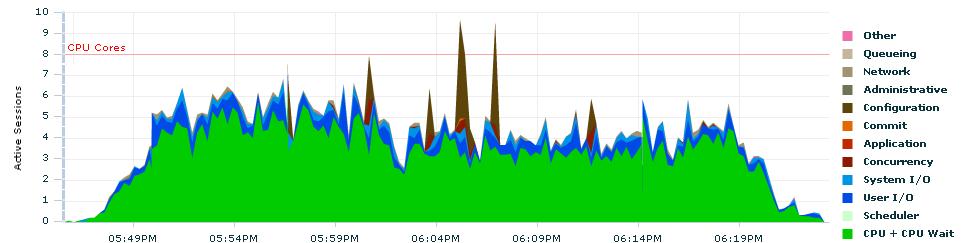
The following chart (you can click on it to increase its size) shows the load generated by 20 parallel processes with default values for COMMIT_WAIT and COMMIT_LOGGING. With the default configutation the system was able to process about 1000 “objects” per second. As you can see there were a lot of waits related to the commit wait class.

Since this was a controlled processing using COMMIT_WAIT was not considered a problem. So, we tested the very same load with COMMIT_WAIT set to NOWAIT and COMMIT_LOGGING set to BATCH. The throughput increased to about 1200 “object” per second. In other words, not dramatically. But, more importantly, as the following chart shows almost all waits in the commit wait class disappeared. This was very important because without that serialization taking place we were able to increase the number of parallel processes.

The following chart shows the load generated by 50 parallel processes. Again, almost no wait related to commits. With 50 processes the system was able to process about 2300 “objects” per second.
In summary, COMMIT_WAIT and COMMIT_LOGGING are not commonly used parameters but, in some specific situations, using them it might be beneficial to avoid wait events related to commits.
Hi Chris,
I was of the opinion that in PL/SQL loops, the default is always BATCH NOWAIT as documented:
“Note:
The default PL/SQL commit behavior for nondistributed transactions is BATCH NOWAIT if the COMMIT_LOGGING and COMMIT_WAIT database initialization parameters have not been set.”
http://docs.oracle.com/cd/E11882_01/appdev.112/e25519/static.htm#LNPLS592
However, your strace findings prove differently.
Thanks for sharing and happy easter,
Martin
@Martin: Chris set the parameter explicitly and was not using the default values, so it seems to work as documented.
I wonder what happens with SCN on RAC case of batch commits? Is SCN broadcasted once per batch? I have no way of testing that. That may be a really significant thing for OLTP performance on RAC.
Hi Martin
As Marcus pointed out, it works as documented. Here is an example where I do not set the parameters:
Cheers,
Chris
[…] Chris Antongnini blogs about the purpose of COMMIT_WAIT and COMMIT_LOGGING parameters from the real world experience. […]
Hi Chris,
Did you ever try to set commit_write to BATCH and left commit_wait default value ?
My colleague spotted (and I have confirmed) that commit write set to BATCH is invisible changing commit_wait to NOWAIT
So in that configuration
user process is not waiting for LGWR confirmation (semtimedop) but it is returning commit command immediately even if LGWR process is stopped
with kill -SIGSTOP command. There is also no sight of “log file sync” in 10046 trace file.
I have tested it in 11.2.0.2 but I’m wondering if it happen as well in your configuration.
regards,
Marcin
A couple more little points to watch out for:
a) when you change commit_logging from immediate to batch Oracle changes the content of the redo entries it generates. (You can see this in the stats “redo entries” and “redo size” – and confirm it with a log file dump.
b) the standard pl/sql commit is NOT the same as any of the four combinations available through these two parameters; there is a fifth code path. (ditto re stats and dumps)
Useful post. Thanks !
Hemant
Hi all,
I’m confused about the COMMIT_LOGGING parameter… Can “D”urability requirement be violated by this parameter?
Regards,
Giuseppe.
Ciao Giuseppe
As I wrote in the post, D might be violated only when is set to NOWAIT.
Best,
Chris
Hi Chris,
thanks for helping me…
Your blog is really interesting.
Regards,
Giuseppe.
[…] Chris Antongnini blogs about the purpose of COMMIT_WAIT and COMMIT_LOGGING parameters from the real world experience. […]
Excellent post! These parameters saved me when I was doing a production migration under very stressful conditions. This article validated my belief that we can use these parameters in certain situations.
Thanks,
Murali
Hi Christian,
Wondered whether the parameters were utilized during migration of “DMS to a new version” where all were “INSERT” operations ONLY – that were generated by the “migration tool”?
Thanks in advance.
Regards,
Anar
Hi Anar
I don’t remember exactly, but what I do remember is that the code used for migrating the data was not modifiable. In other words, it was shipped with the product. I guess that most of the operations were INSERT statements.
Best,
Chris
Thanks Christian for the details.
Might the product have been with database of multivalue nature ( t 24 ) ? :)
[…] COMMIT_WAIT and COMMIT_LOGGING […]
[…] I was surprised to find this, for me it meant I was searching for ‘kcrf_commit_force_int’ in the debugtrace of a commit with the ‘write batch’ arguments, and not finding any of them. Actually, this has been reported by Marcin Przepiorowski in a comment on an article by Christian Antognini on this topic. […]
[…] To clearly understand how those two parameters work, you can first read this nice article from my colleague Chris Antognini. here […]